Running my Personal AI Assistant Stack for Less Than a Sandwich a Month
1. Running my personal AI Assistant Stack for Less Than a Sandwich a Month
Not a demo. Not a proof of concept. This is the setup I use every day. It polish my blog posts, and answers my questions. It has memory across sessions. It searches the web. It speaks to me on Telegram.
It costs less than a falafel sandwich in the West. Call it eight euros. Call it nine dollars.
And when I stop talking to it, it turns itself off.
2. This Was Not a Blueprint. It Was an Evolution.
I did not sit down and design this architecture on a whiteboard. I arrived here one problem at a time.
The first problem was running Hermes on my laptop. I was not willing to give an AI agent a shell on my personal machine. So I ran it into a container. Isolation solved the security problem but created a new one. My laptop had to stay on. That was fine for an afternoon. It was not fine overnight.
The obvious fix was a cloud VM. I picked AWS EC2 because a t2.micro was cheaper than any managed hosting box I could find.
Then came the LLM problem. I started hitting rate limits on the usual providers. I do not want to be throttled mid-conversation while an agent is halfway through a multi-step task. I searched, I tested, and I landed on DeepSeek. Their V4 Pro model matched GPT-4 class reasoning at a fraction of the cost and with zero rate-limit friction for my usage. That single switch unlocked the whole pattern. Cheap compute, cheap inference.
The interface came next. I connected Hermes to Telegram with a free bot token. Now I could message my agent from anywhere. No terminal. No SSH. Just a chat.
At this point the stack worked. But it was also bleeding money while I slept. A t2.micro running 24 hours a day, 30 days a month, plus the EBS volume. That is around ten dollars before you send a single message. I was only active for four or five hours a day. The rest was waste.
So I built the auto-shutdown.
3. The Architecture
The stack has four moving parts.
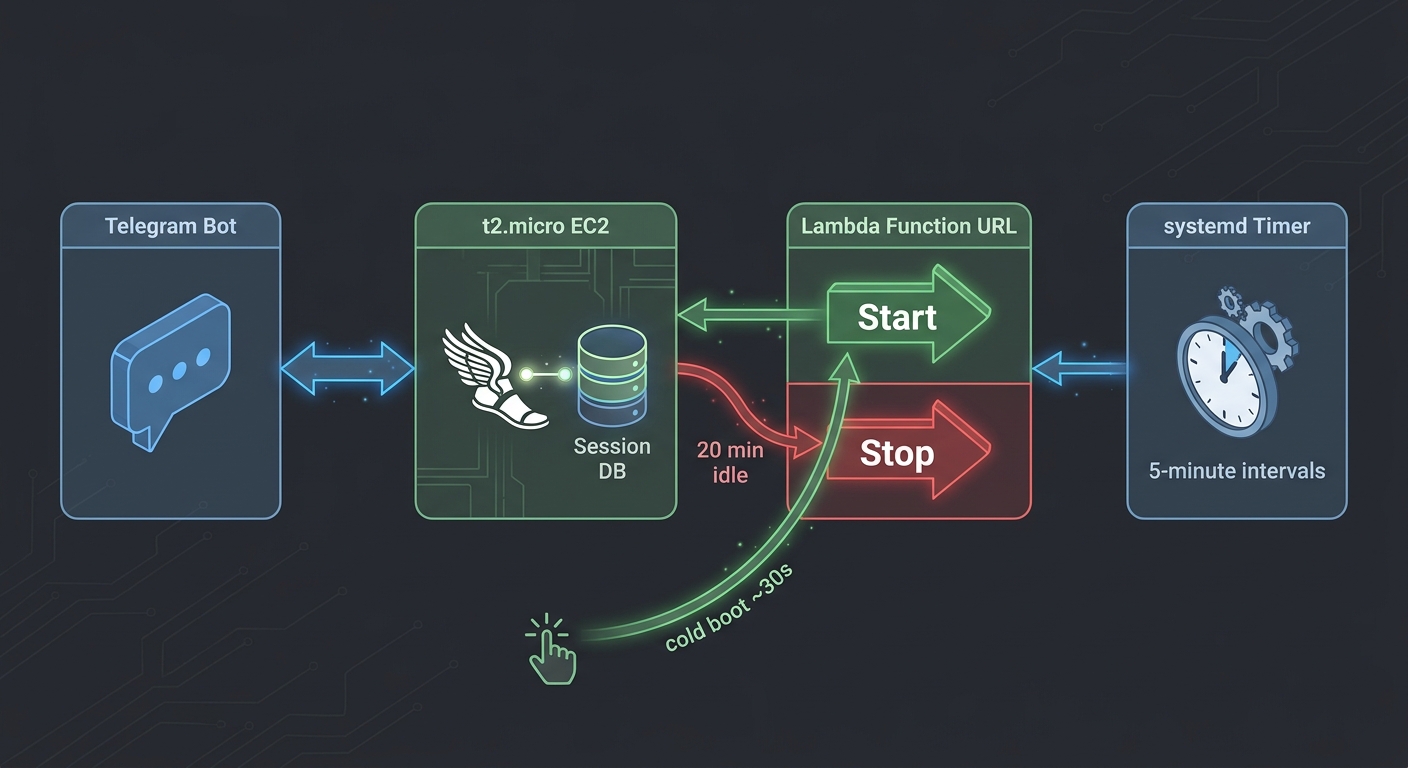
An EC2 t2.micro runs Hermes Agent. It holds my session history, my custom skills, and my persistent memory. It has access to my terminal, my filesystem, my GitHub, and the web. That access is governed by Hermes's own tool security, not by AWS IAM. There is no IAM role attached to this instance.
Two AWS Lambda functions manage the lifecycle. They sit behind a single Function URL that accepts a JSON body with an action field. Send {"action": "stop"} and the Lambda calls the EC2 StopInstances API against this one instance. Send {"action": "start"} and it starts it back up. The Lambda's IAM role has exactly two permissions. ec2:StartInstances and ec2:StopInstances. Nothing else can be called. Nothing else can be reached.
A systemd timer fires every five minutes on the EC2 instance. It runs a bash script that queries the last message timestamp across all Hermes profile databases. Two stages. First, has any user sent a message in the last twenty minutes. Second, has the agent itself been active. Writing tool outputs, responding, running background tasks. In the last twenty minutes. Only when both checks come back silent does the script fire a Telegram notification and then curl the Lambda stop endpoint.
The boot-up flow is a link. I have it bookmarked on my phone. One tap, a thirty-second wait while the machine starts and Hermes initializes, and then I message my agent on Telegram like nothing happened.
The shutdown flow is a notification. A Telegram message arrives. "Hermes idle shutdown. No messages for 25 minutes." There is a restart link in the message. If I ignore it, the machine stops. If I tap it, the cycle begins again.
4. Least Privilege Is Not a Buzzword Here
Most cloud servers have a trail of credentials. IAM roles with sweeping permissions. Environment variables stuffed with access keys. Database connection strings in config files. SSH keys shared across machines.
This machine has none of that.

No IAM role. No AWS access key or secret key anywhere on the filesystem. No database password. No SSH key that leads anywhere else. The security group has exactly one inbound port open. SSH. That is it. All other ports are closed at the AWS firewall level.
The only credentials on this machine are API keys for LLM providers. DeepSeek. Kimi. Mistral. And I treat them the way they deserve to be treated. Prepaid credit. Small balances. If someone compromises this machine and extracts every key, the blast radius is measured in pocket change. They drain my DeepSeek credit. I lose maybe five dollars. That is the entire attack surface.
There is no pivot path. You cannot move from this machine to my AWS account. You cannot reach my other infrastructure. You cannot escalate privileges because there are no privileges to escalate into. The machine talks to the LLM APIs. It talks to Telegram. It talks to the Lambda Function URL for shutdown. Everything else is blocked.
This is not a theoretical posture. I ran through the scenario. If someone gets root on this instance, what do they have. A few bucks of prepaid LLM credit and a conversation history of my career questions and blog drafts. The damage is financial and capped at the prepaid balance. The privacy exposure is limited to what I chose to share with my agent. That trade-off is acceptable to me. It might not be for everyone. But it is honest.
5. The Sandwich Math
Here is the actual breakdown.

EC2 t2.micro, on-demand pricing is roughly $0.0126 per hour. I use it four to five hours a day. That is $1.50 to $1.90 per month for compute. The EBS gp3 volume is another twenty cents. A few cents for IO. Call the EC2 side two dollars.
DeepSeek V4 Pro. This is my main model. I use it for content creation, code review, research, and multi-step agent tasks. In a typical month I spend two to three dollars on API calls. Their pricing is aggressively cheap and I have never hit a rate limit.
Kimi. I keep a separate profile for certain tasks. Similar cost. Two to three dollars.
Mistral Medium. I have a profile set up but in practice I use the free tier and have not exceeded it.
The two Lambda functions. The start Lambda fires once or twice a day. The stop Lambda fires once or twice a day. Together they generate maybe sixty invocations a month. AWS free tier covers a million. These cost zero.
The Telegram bot. Zero. A free bot token is all you need.
Total. Two dollars for the machine. Five dollars for the LLMs. A few dimes for EBS and IO. Under eight dollars. Under eight euros. A falafel sandwich in Rotterdam runs between seven and nine euros depending on where you go. My AI agent stack costs less.
6. The Idle Tax
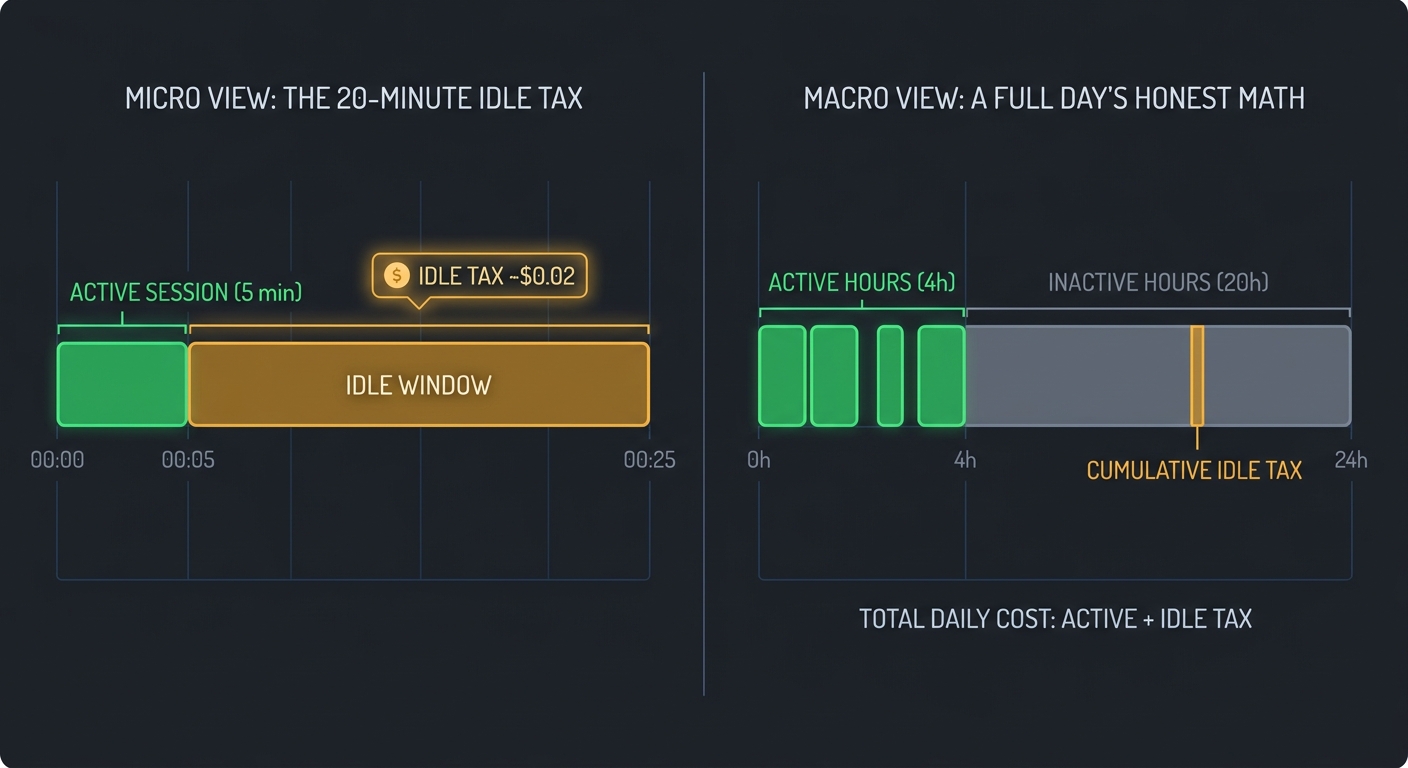
The auto-shutdown works. But it is not instantaneous. There is a twenty-minute idle threshold before the machine stops. That threshold exists for good reason. If the agent is mid-task, a long build, a multi-step research loop, a subagent churning through code, the overall-activity check prevents a kill. The machine only stops when both I and the agent have been silent for twenty minutes.
The downside is predictable. I check in for a five-minute conversation. I get my answer. I close Telegram. The machine runs for another twenty minutes before shutting down. That is twenty minutes of compute I paid for without using.
Multiply that by two or three short sessions a day and the idle tax might add another ten to fifteen hours of runtime per month. On a t2.micro that is maybe forty cents. Not nothing. But also not a reason to abandon the architecture.
The real question is whether the threshold should be shorter. Could I drop it to ten minutes. Probably. The two-stage check protects against mid-task shutdowns regardless of the window. A shorter threshold just means more aggressive cost savings and more frequent cold starts. It is a tuning knob, not a design flaw. I left it at twenty minutes because the cost of a few extra minutes per session was lower than the annoyance of the machine shutting down while I was still thinking about my next message.
7. You Cannot Just Message It From Your Phone
When the machine is asleep, you cannot pick up your phone and type "hey agent, summarize my inbox." You cannot ask it a question from bed and get an instant reply. The start link must be tapped first. Then thirty seconds pass while the EC2 instance boots, Hermes initializes, and the Telegram bot reconnects. Then you can talk.

This is the trade-off. The architecture buys you a sub-ten-dollar monthly bill in exchange for a thirty-second delay at the start of every session. For my usage patterns, that trade-off is easy. I am usually at my desk when I need the agent. I tap the link, finish my coffee, and by the time I am ready the agent is too.
But it does mean the agent is not ambient. It is not a background presence you can ping at any moment. If your use case requires always-on availability, if you want the agent monitoring feeds, answering questions on demand, running scheduled tasks, this architecture will frustrate you. The cold start is the cost of not paying for idle. There is no way around that without keeping the machine running.
8. What This Is. And What It Is Not.
This architecture works for me. It might work for you. It will not work for everyone.
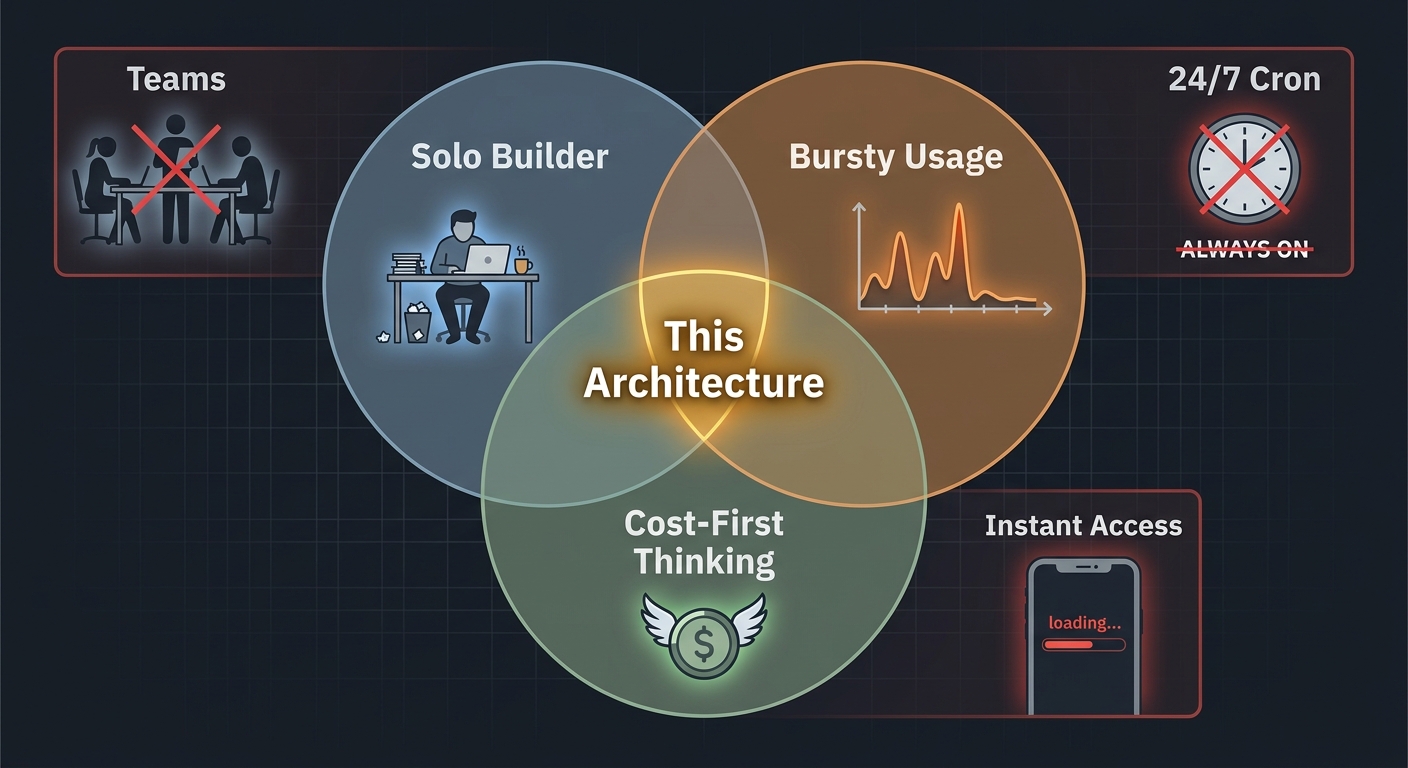
It works if you are a solo builder who uses an AI agent in bursts. You open it for a few hours of focused work. You close it. The machine follows. Your bill breathes with your usage.
It does not work for teams. The agent is bound to one user on one Telegram bot. There is no multi-tenancy. No access control beyond the single chat.
It does not work for scheduled automation. Cron jobs require a running gateway. When the machine is stopped, nothing fires. I do not have cron workflows I depend on. You might. If you need the agent to check your calendar every morning or monitor a feed every hour, this architecture will miss every event while you sleep.
It does not work for instant access. The thirty-second cold start is real. If you want an agent that answers in two seconds from your lock screen, you will have to keep the machine running. And pay for it.
The security posture is appropriate for my threat model. Prepaid LLM keys. No AWS credentials. Closed ports. IMDSv2. I sleep fine. If your threat model involves state actors or regulated data, you have different problems and this post is not your guide.
This architecture is opinionated. It assumes you are an AI-native builder who understands the tools and can debug them when they break. It assumes you are comfortable with bash scripts, systemd timers, and Lambda function URLs. Those assumptions are not universal. They are specific. And they are mine.