Build Product, Not Infrastructure
Build Product, Not Infrastructure
1. The Interview That Changed Nothing (But Clarified Everything)

I interviewed at a company with a polished SaaS product, paying customers, and zero DevOps hires. No Kubernetes cluster. No dedicated web servers. No one on call for infra. They embraced managed services fully, and their bill breathes with their traffic.
I walked out thinking not that I had discovered something new, but that I had finally seen it done cleanly. No half measures. No "we'll migrate later." Just a team building product while the cloud provider ran the plumbing.
I have seen the opposite too many times. A seed-stage startup with four engineers and a dedicated K8s cluster. An early-stage team burning two sprints on CI/CD pipeline configuration before they had a single paying user. A CTO who could explain their autoscaling policy in detail but could not tell you why churn was 12%.
2. What "No Ops Culture" Actually Means
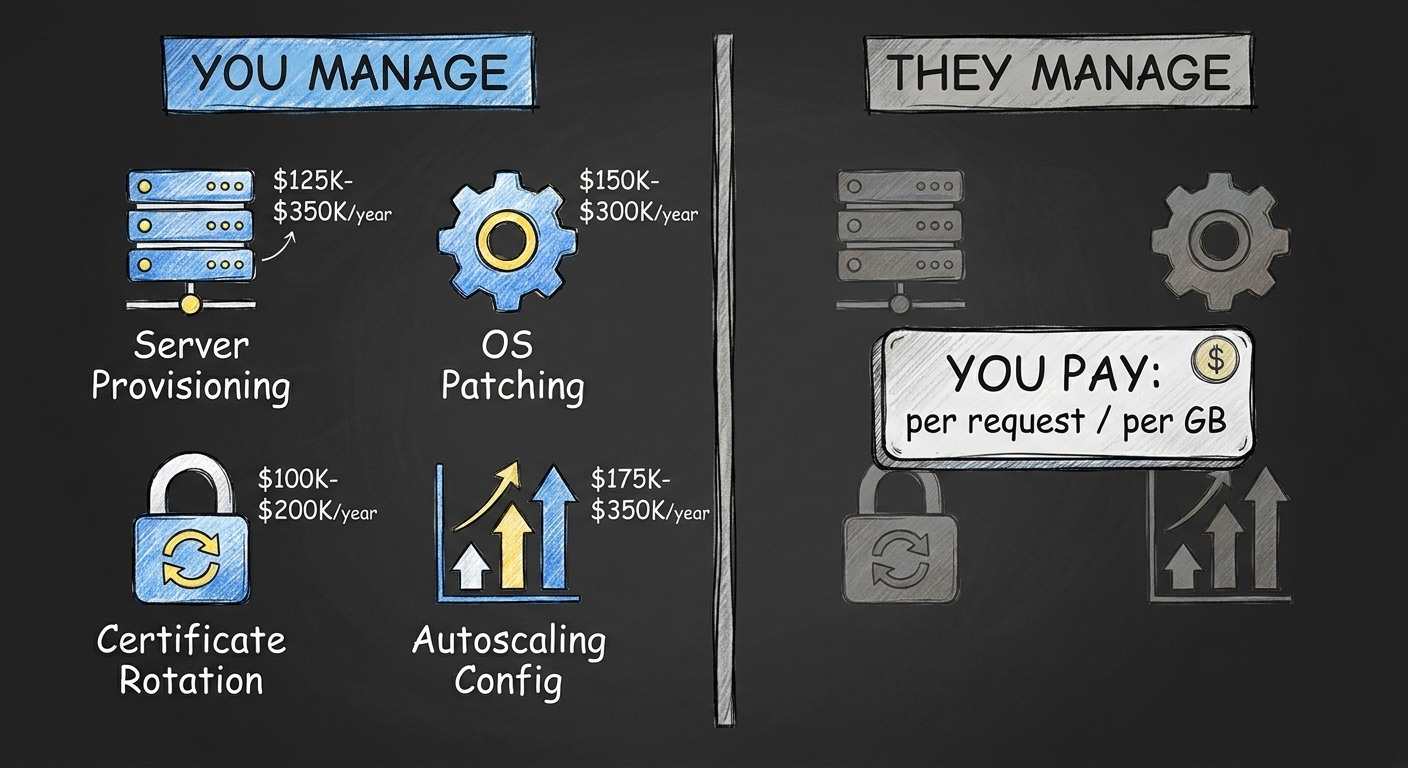
"No ops" does not mean operations work disappears. It means you pay a premium per request so you do not pay a salary for uptime. Someone is still restarting containers, rotating certificates, patching vulnerabilities. That someone just works for Google or Amazon now, not for you.
The math is straightforward. A DevOps engineer in the US costs $125,000 to $140,000 in base salary. Total comp pushes past $175,000. Most teams need at least two people for on-call rotation and bus factor. That is $350,000 a year before you have provisioned a single server.
Meanwhile, a startup running on Cloud Run and Cloud SQL can serve thousands of users for under $500 a month. The managed premium is real. The salary you are not paying is realer.
This only works if your architecture fits the managed model. Long-running background jobs, unpredictable cold starts, GPU compute. These are still hard on managed services. But for the vast majority of seed-stage workloads (web apps, APIs, async workers, standard relational data), the fit is clean.
3. None of This Is New. And That Is the Frustrating Part.
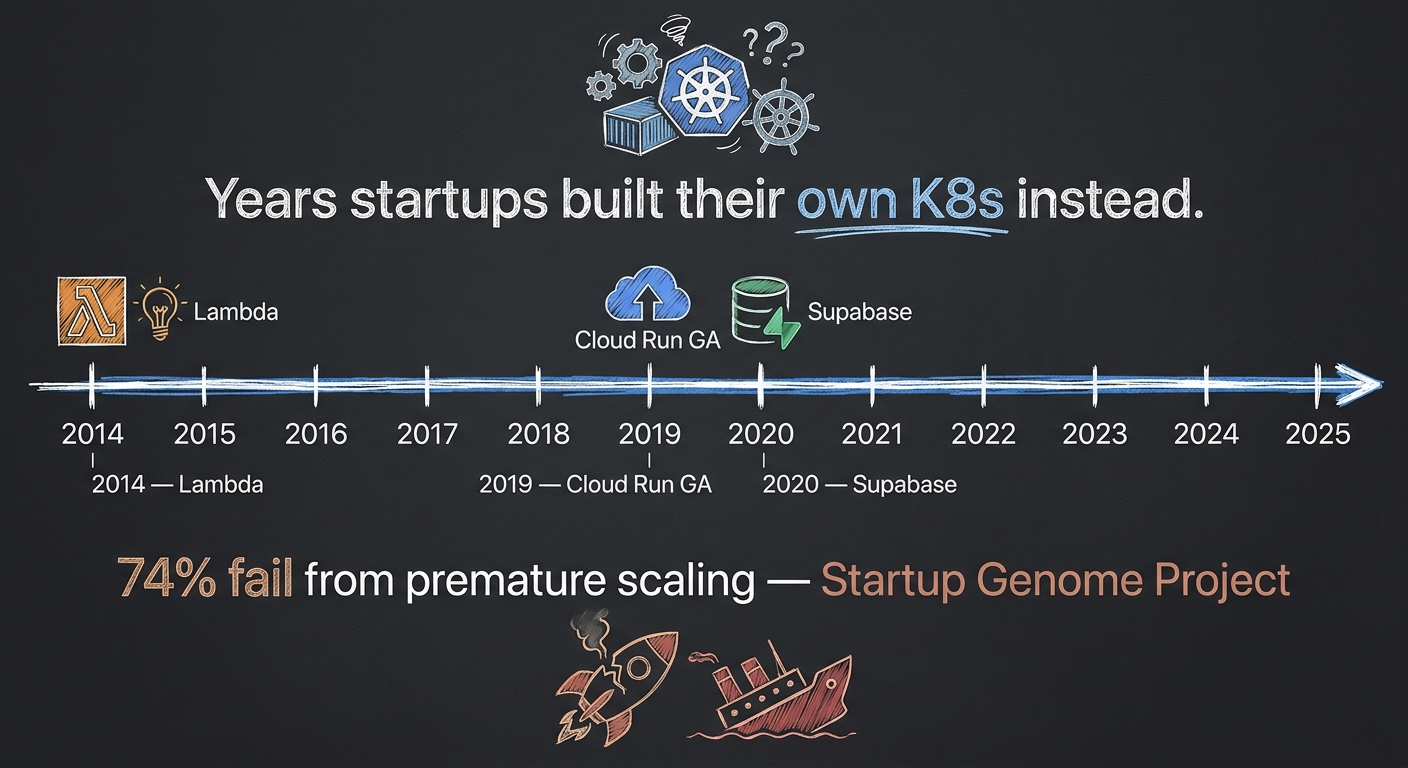
AWS Lambda launched in November 2014. Eleven years ago. Cloud Run hit GA in late 2019. Six years ago. Cloud SQL, RDS, Firebase. These are mature, battle-tested services that run production workloads at companies you use every day.
And still, seed-stage startups open with a Kubernetes cluster.
The justification is always the same. "We'll need it eventually." "Managed services get expensive at scale." That last one is technically true and completely irrelevant for the first two years.
The Startup Genome Project studied 3,200 startups. Their finding: premature scaling was the single strongest predictor of failure. Not competition. Not funding. Scaling before you are ready. Failed startups wrote 3.4 times more code before product-market fit than successful ones. Most of that code was infrastructure. CB Insights updated the data in 2025. Same pattern. 70% of tech startups fail by month 20, primary cause unchanged.
The cloud providers spent a decade building services to delay that scaling decision. We ignore them.
4. The Real Damage of Going Raw Too Early
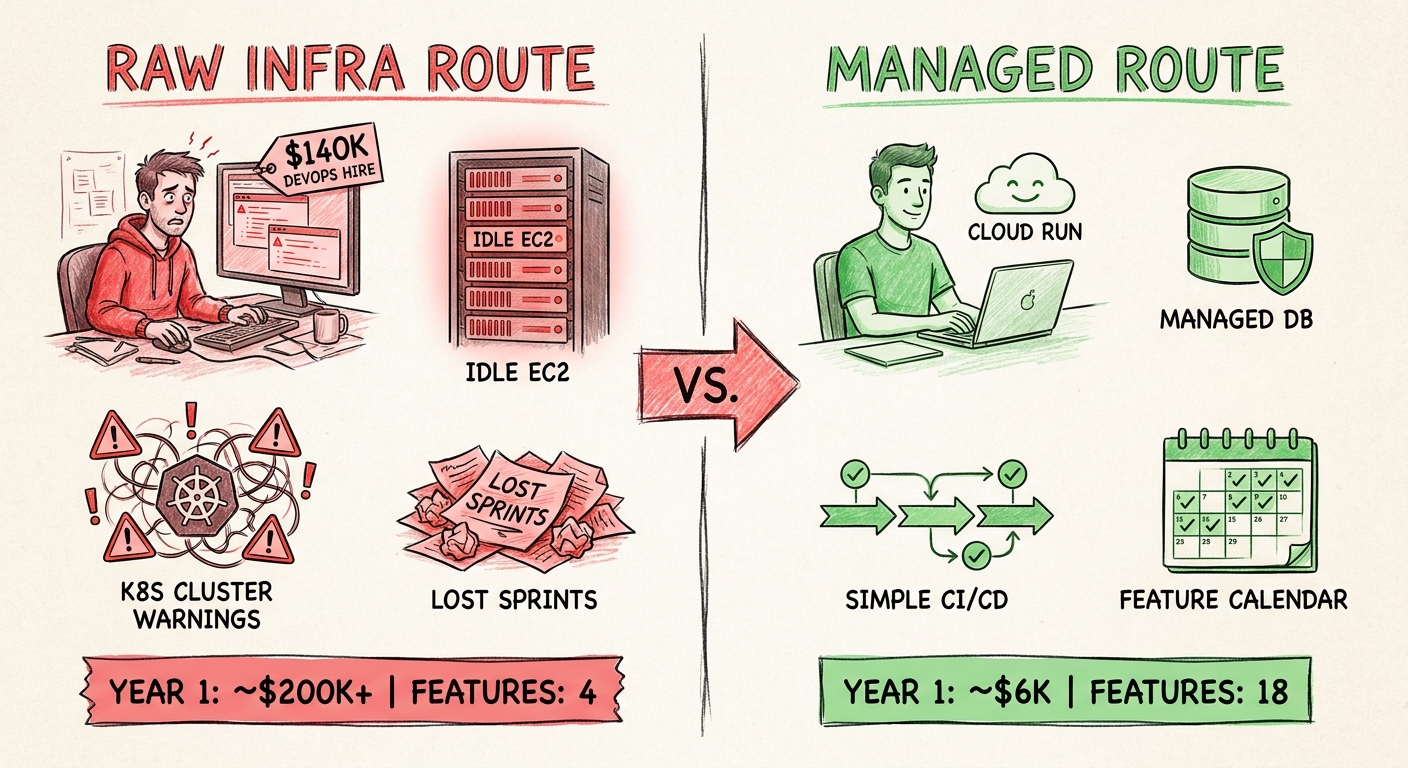
The obvious cost is the cloud bill. EC2 instances running 24/7 cost money whether serving traffic or not. The less obvious cost is the person you hired to manage them.
That $140,000 DevOps hire. In a four-person startup, that is 25% of your engineering budget going to zero features, zero user-facing improvements, zero product differentiation. Your users cannot tell whether your app runs on EKS or Cloud Run. They can tell whether it shipped on time.
Every hour spent debugging Terraform state conflicts is an hour not spent on the core product. Every sprint burned on K8s version upgrades is a sprint your competitor spent shipping. After six months, they have more features, more user feedback, more iterations. You have a nice CI/CD pipeline and a smaller user base.
A team I know migrated from AWS to Vercel. Same app. Same users. Monthly bill: $12,000 became $140. 98% reduction. The bigger gain: their engineers stopped managing infrastructure and started building product again. That does not show up on an invoice, but it shows up in shipping velocity within weeks.
5. The Managed Stack That Ships
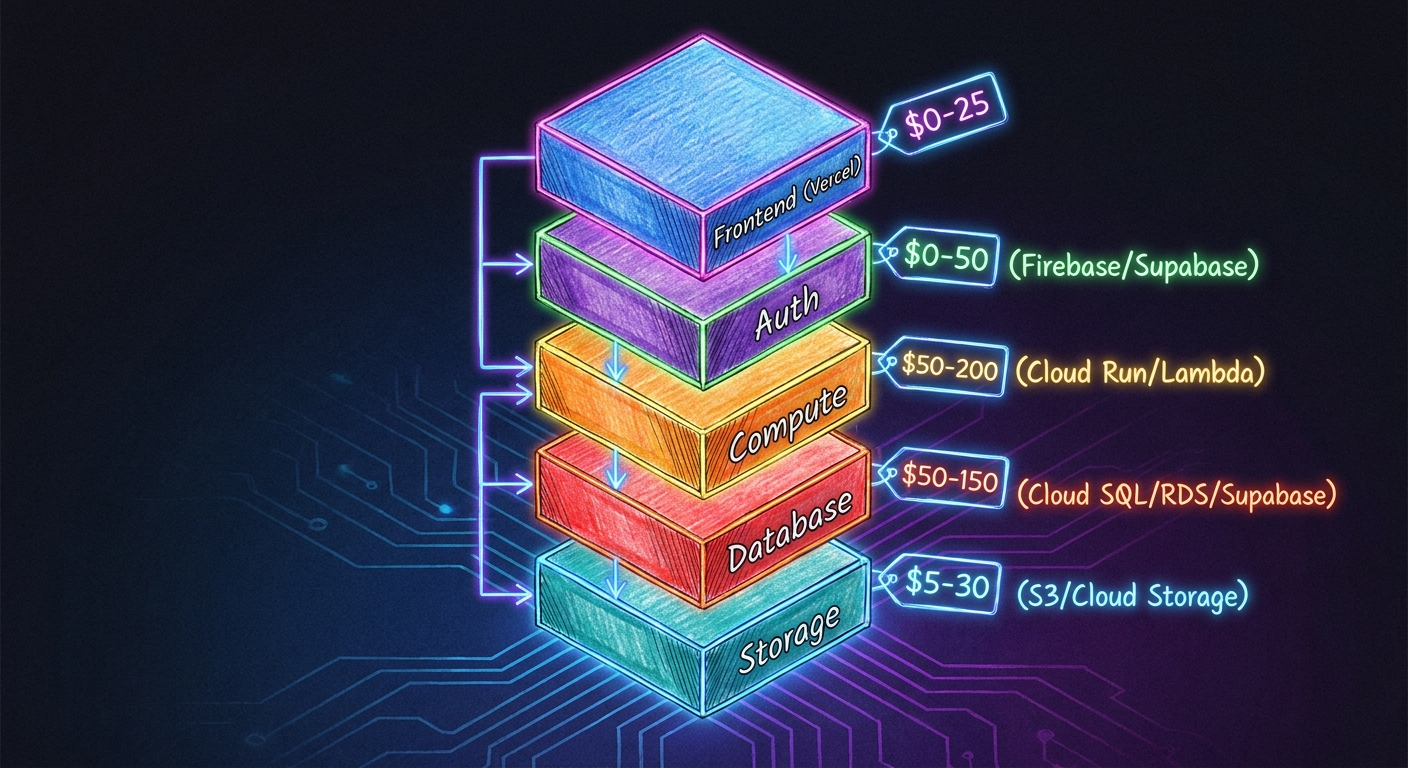
Compute: Cloud Run (HTTP, long-ish requests) or Lambda (event-driven). Both scale to zero. No traffic, no bill.
Data: Cloud SQL, RDS, or Supabase. Backups, replication, failover handled. You still own indexes and queries. You do not own disk failure.
Auth: Firebase Auth or Supabase Auth. OAuth, sessions, password resets. Solved problems. Do not build your own.
Frontend and CDN: Vercel or Cloudflare Pages. Global delivery, auto SSL, preview deploys per branch.
This stack runs $50 to $500 a month at early-stage traffic. It handles thousands of users with zero on-call rotation.
What it does not do: fine-grained networking, custom binaries, long-running jobs beyond platform timeouts, cheap GPU compute. If your product genuinely needs those, managed may not fit. But verify the need before you build for it. Most startups that think they need a custom WebSocket server just need Cloud Run with session affinity turned on.
If you have built on both sides of this line, or if you tried managed services and hit a wall I am not seeing, I want to hear about it. Follow me on LinkedIn for more honest takes on infra, AI, and building in public.
6. When Managed Services Don't Apply

If your product handles sensitive personal data under GDPR, HIPAA, or equivalent regulation, managed services get complicated. Google Cloud and AWS offer BAA support for a subset of services. It is never the full catalog. Compliance overhead does not disappear. You still configure access controls, audit logging, encryption. The platform gives you the levers, but you pull them.
Data residency requirements shrink your options further. Not every Cloud Run region exists everywhere. You may genuinely need dedicated infrastructure with auditable physical access.
In these cases, an infrastructure team is not premature optimization. It is compliance. It applies from day one if your product touches regulated data. You do not get a grace period.
There is a middle ground: managed services for non-sensitive workloads, a focused ops team for the compliant core. The auth service on Cloud Run with no PII. Patient data on a dedicated, audited PostgreSQL instance. More work than pure managed, less than building everything from scratch.
7. The Inflection Point
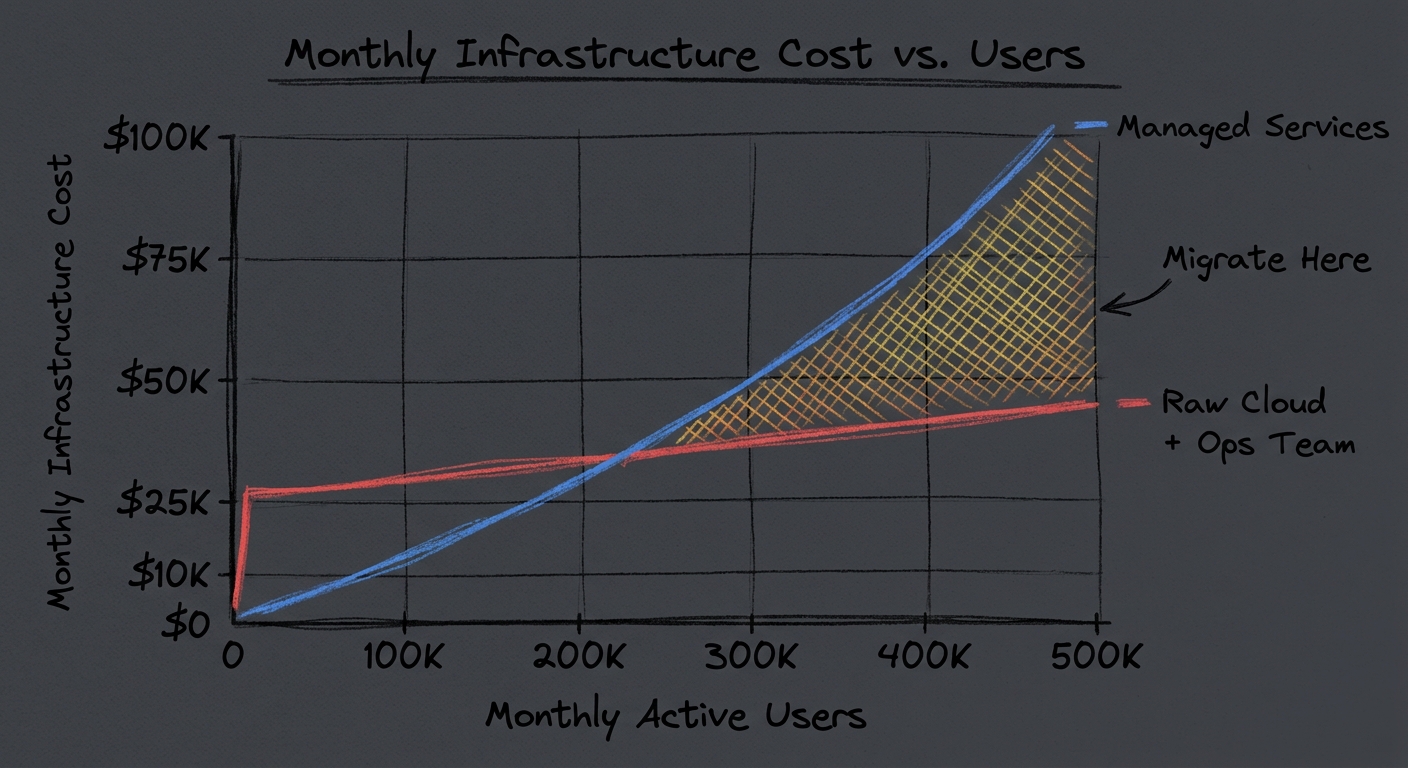
Managed services are not forever. At some scale, the per-request premium becomes a line item your CFO asks about.
The signal: when your managed bill crosses the fully loaded cost of a small ops team, and the gap keeps growing. $15,000 a month on Cloud Run? Ops team costs $25,000. Stay managed. $80,000 a month and growing 20% monthly? Time to plan a migration.
Most teams migrate too early. They see a $3,000 bill and picture raw EC2 savings. They forget the salary they are about to add, the velocity they will lose during migration, the traffic patterns that will invalidate their capacity planning within a quarter.
The playbook: start fully managed. At $20,000 a month, run the numbers. At $50,000 a month or when platform limits block a feature, start migrating. The cost of migrating too early is months of distracted engineering. The cost of migrating too late is a slightly larger bill for a few more months. Those are not symmetric risks.
8. What I Am Still Watching: AI-Native Infrastructure

LLM inference is still in its raw-infrastructure phase. GPU instances, model weights, cold starts. Managed services are emerging (Replicate, Modal, Fireworks) but the space is young.
What I am waiting for is the Lambda moment for LLMs. Deploy a model, pay per inference, scale to zero. Load only the fraction of model weights you need, not the entire 70GB checkpoint. Someone else handles redundancy and capacity.
Mixture of Experts architectures show this is possible. The infrastructure to serve models that way on demand does not exist yet. But it is coming. When it arrives, the teams building their own GPU clusters today will look like the teams building their own K8s clusters in 2019. Necessary at the time, expensive in retrospect.
9. References
- Startup Genome Project (2011). "Premature Scaling: The Leading Cause of Startup Failure." 3,200 startups, Berkeley/Stanford.
- CB Insights (2025). "The Top 12 Reasons Startups Fail." 470+ startup post-mortems.
- AWS. "AWS Lambda Turns Ten: The First Decade of Serverless Innovation." AWS Blog, November 2024.
- Google Cloud. "Cloud Run General Availability." InfoQ, November 2019.
- Underdog.io (2026). "DevOps Engineer Salary Guide." Average US base: $139,000.
- Sealos (2025). "Vercel vs AWS: Total Cost of Ownership Comparison."
- "Our $12K AWS Bill Became $140 on Vercel." Medium / Let's Code Future, 2025.
- Bytebase (2026). "Supabase vs AWS: Feature and Pricing Comparison."
- PwC (2025). "Why 70% of Tech Startups Fail by Month 20."